Excel-TippPIVOTMIT-Funktion Schritt für Schritt erklärt
Mit der Einführung der PIVOTMIT()-Funktion erweitert Excel sein Repertoire an Analysewerkzeugen. Wer bisher Pivot-Tabellen einsetzt und manchmal eine gewisse Abneigung gegenüber ihrer Komplexität verspürt hat, wird diese Neuerung zu schätzen wissen.
PIVOTMIT() vereinfacht die Erstellung und Nutzung von Pivot-Tabellen in einer Weise, die selbst Excel-Profis staunen lässt. In diesem Beitrag erfahren Sie, wie PIVOTMIT() funktioniert und warum diese Funktion die Art und Weise, wie sich Daten analysieren lassen, revolutionieren wird.
Die PIVOTMIT()-Funktion ist eine der dynamischen Matrixfunktionen in Excel, die es Ihnen ermöglicht, Pivot-Tabellen direkt in einer Zelle zu erstellen – ohne den klassischen Dialog für Pivot-Tabellen oder manuelles Layout-Design.
Syntax der PIVOTMIT()-Funktion
Die Syntax von PIVOTMIT() ist simpel und flexibel gestaltet:
=PIVOTMIT(row_fields; col_fields; values; function; [field_headers]; [row_total_depth]; [row_sort_order]; [col_total_depth]; [col_sort_order]; [filter_array]; [relative_to])
Zur Bedeutung dieser Parameter der PIVOTMIT()-Funktion:
row_fields – Zeilenfelder der Pivot-Tabelle: Ein spaltenorientiertes Array oder ein Bereich, der die Werte enthält, die zum Gruppieren von Zeilen und Generieren von Zeilenüberschriften verwendet werden. Das Array oder der Bereich kann mehrere Spalten enthalten. Wenn ja, enthält die Ausgabe mehrere Zeilengruppenebenen.
col_fields – Spaltenfelder der Pivot-Tabelle: Ein spaltenorientiertes Array oder ein Bereich, der die Werte enthält, die zum Gruppieren von Spalten und Generieren von Spaltenüberschriften verwendet werden. Das Array oder der Bereich kann mehrere Spalten enthalten. Wenn ja, weist die Ausgabe mehrere Spaltengruppenebenen auf.
values – Werte der Pivot-Tabelle: Ein spaltenorientiertes Array oder ein Bereich der zu aggregierenden Daten. Das Array oder der Bereich kann mehrere Spalten enthalten. Wenn ja, enthält die Ausgabe mehrere Aggregationen.
function – Aggregationsfunktion für die Werte der Pivot-Tabelle, wie zum Beispiel: SUMME / PROZENTVON / MITTELWERT / MEDIAN / ANZAHL / ANZAHL2 / MAX / MIN / PRODUKT / MATRIXZUTEXT / TEXTKETTE / STABW.S / STABW.N / VAR.S / VAR.P / MODUS. EINF / LAMBDA. Diese Funktion definiert, wie die Werte (values) aggregiert werden.
field_headers: Eine Zahl, die angibt, ob die row_fields, col_fields und Werte Header aufweisen und ob Feldüberschriften in den Ergebnissen zurückgegeben werden sollen. Die folgenden Werte sind möglich:
- Fehlt: automatisch (Standard)
- 0: Nein, enthält keine Spaltenüberschrift
- 1: Ja, enthält Spaltenüberschrift, aber nicht anzeigen
- 2: Nein, enthält keine Spaltenüberschrift, aber Spaltenüberschrift generieren
- 3: Ja, enthält Spaltenüberschrift und anzeigen
Hinweis: Bei „Automatisch“ wird davon ausgegangen, dass die Daten Header basierend auf dem Values-Argument enthalten. Wenn der 1. Wert Text ist und der 2. Wert eine Zahl ist, wird davon ausgegangen, dass die Daten Header aufweisen. Feldüberschriften werden angezeigt, wenn mehrere Zeilen- oder Spaltengruppenebenen vorhanden sind.
row_total_depth: Bestimmt, ob die Zeilenüberschriften Summen enthalten sollen. Die folgenden Werte sind möglich:
- Fehlt: automatisch, Gesamtsummen und nach Möglichkeit Zwischensummen (Standard)
- 0: Keine Gesamtsummen
- 1: Gesamtsummen
- 2: Gesamt- und Zwischensummen
- -1: Gesamtsummen oben
- -2: Gesamt- und Zwischensummen oben
Hinweis: Bei Teilergebnissen müssen row_fields mindestens zwei Spalten aufweisen. Zahlen, die größer als 2 sind, werden unterstützt, sofern row_field über ausreichende Spalten verfügt.
row_sort_order: Eine Zahl, die angibt, wie Spalten sortiert werden sollen. Zahlen entsprechen den Spalten in row_fields, gefolgt von den Spalten in Werten (values). Wenn die Zahl negativ ist, werden die Zeilen in absteigender/umgekehrter Reihenfolge sortiert.
- Fehlt: automatisch, die Sortierung erfolgt aufsteigend oder alphabetisch nach der ersten Spalte (Standard)
- 1: die erste Spalte aus row_fields wird aufsteigend, alphabetisch von A bis Z sortiert
- -1: die erste Spalte aus row_fields wird absteigend, alphabetisch von Z bis A sortiert
- 2: die zweite Spalte aus row_fields wird aufsteigend, alphabetisch von A bis Z sortiert
- -2: die zweite Spalte aus row_fields wird absteigend, alphabetisch von A bis Z sortiert
- …
Ein Zahlenvektor kann bei der Sortierung nur basierend auf row_fields bereitgestellt werden.
col_total_depth: Bestimmt, ob die Spaltenüberschriften Summen enthalten sollen. Die folgenden Werte sind möglich:
- Fehlt: automatisch, Gesamtsummen und nach Möglichkeit Zwischensummen (Standard)
- 0: Keine Gesamtsummen
- 1: Gesamtsummen
- 2: Gesamt- und Zwischensummen
- -1: Gesamtsummen oben
- -2: Gesamt- und Zwischensummen oben
Hinweis: Bei Teilergebnissen müssen col_fields mindestens 2 Spalten aufweisen. Zahlen, die größer als 2 sind, werden unterstützt, sofern col_field über ausreichende Spalten verfügt.
col_sort_order: Eine Zahl, die angibt, wie Zeilen sortiert werden sollen. Zahlen entsprechen Spalten in col_fields, gefolgt von den Spalten in Werten (values). Wenn die Zahl negativ ist, werden die Zeilen in absteigender/umgekehrter Reihenfolge sortiert.
- Fehlt: automatisch, die Sortierung erfolgt aufsteigend oder alphabetisch nach der ersten Spalte (Standard)
- 1: die erste Spalte aus col_fields wird aufsteigend, alphabetisch von A bis Z sortiert
- -1: die erste Spalte aus col_fields wird absteigend, alphabetisch von Z bis A sortiert
- 2: die zweite Spalte aus col_fields wird aufsteigend, alphabetisch von A bis Z sortiert
- -2: die zweite Spalte aus col_fields wird absteigend, alphabetisch von A bis Z sortiert
- …
Ein Zahlenvektor kann bei der Sortierung nur basierend auf col_fields bereitgestellt werden.
filter_array: Einspaltiges Feld mit Wahrheitswerten (WAHR/FALSCH), das angibt, ob die entsprechende Datenzeile berücksichtigt werden soll. Das Feld muss genauso viele Einträge wie row_fields haben. Sie können eine Bedingung formulieren, deren Ergebnis wahr oder falsch ist. Zeilen (Datensätze), die als Ergebnis „falsch“ haben, werden bei der Ausgabe nicht angezeigt.
relative_to: Bei Verwendung einer Aggregationsfunktion, die zwei Argumente erfordert, steuert relative_to, welche Werte für das zweite Argument der Aggregationsfunktion bereitgestellt werden. Dies wird in der Regel verwendet, wenn PERCENTOF für die Funktion bereitgestellt wird.
Mögliche Werte sind:
- 0: Spaltensummen (Standard)
- 1: Zeilensummen
- 2: Gesamtsummen
- 3: Übergeordnete Spalte Gesamtsumme
- 4: Übergeordnete Zeile gesamt
Hinweis: Dieses Argument hat nur Auswirkungen, wenn die Funktion zwei Argumente erfordert. Wenn Sie eine benutzerdefinierte Lambda-Funktion für die Funktion bereitstellen, sollte sie dem folgenden Muster folgen: LAMBDA(Teilmenge, Gesamtmenge, SUMME(Teilmenge)/ SUMME(Totalset)).
Ein Praxisbeispiel mit PIVOTMIT()
In der folgenden Abbildung sehen Sie den Ausschnitt aus einer Liste, die mit der Funktion PIVOTMIT() übersichtlich aggregiert werden soll. Die Produktumsätze sollen hierbei nach Filialen (Zeilen) und Produkten (Spalten) summiert dargestellt werden.
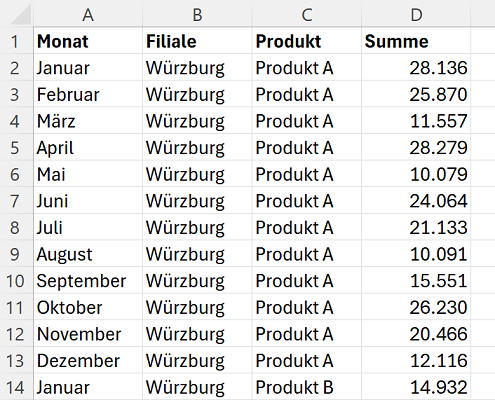
Für diese Aufgabenstellung können Sie die Funktion PIVOTMIT() wie folgt einsetzen:
=PIVOTMIT(B1:B109;C1:C109;D1:D109;SUMME)
- B1:B109 = row_fields = Zeilen der Pivot-Tabelle
- C1:C109 = col_fields = Spalten der Pivot-Tabelle
- D1:D109 = values = Werte der Pivot-Tabelle
- SUMME = function = Aggregatfunktion, die auf die Werte angewendet wird
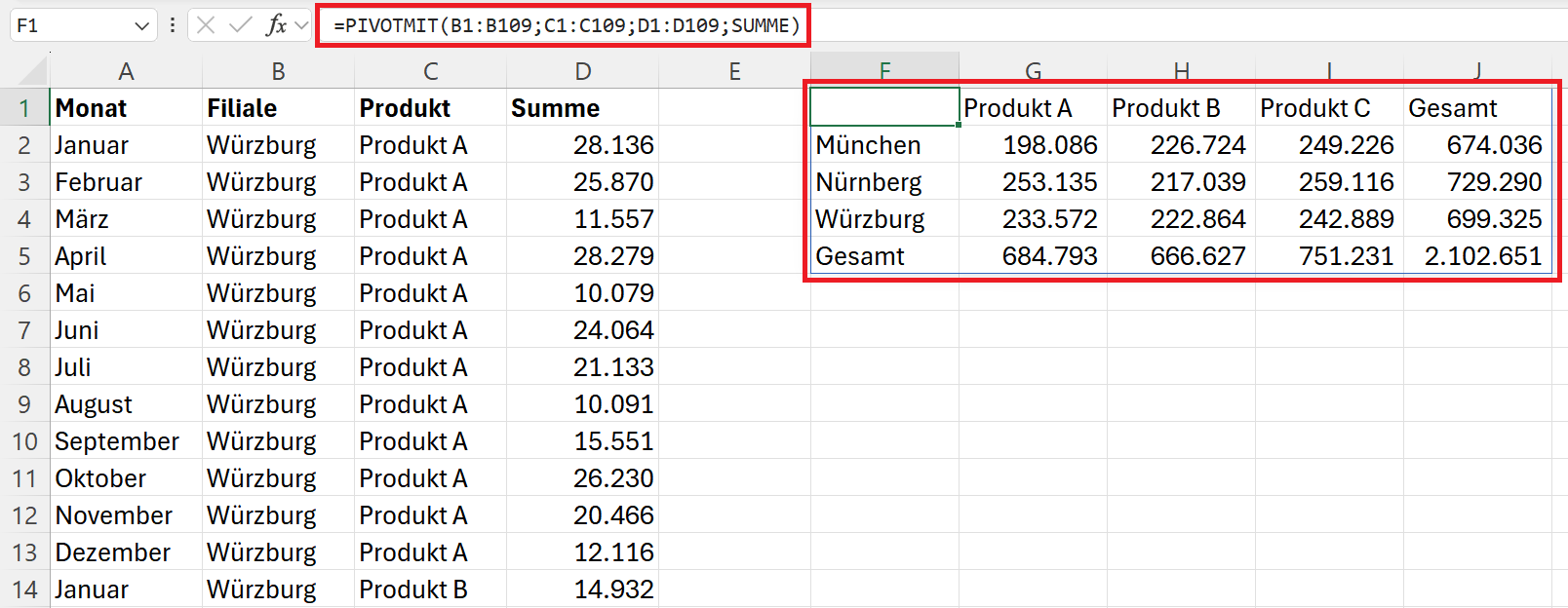
Diese einfachste Anwendung der PIVOTMIT()-Funktion summiert alle Werte in der Umsatzspalte nach Filiale (Zeile) und Produkten. Dies geschieht automatisch und ohne manuelle Sortierung oder Filterung.
Weitere interessante Parameter der Funktion PIVOTMIT()
Spalten- und Zeilenüberschriften anzeigen
Über das Argument field_headers können Sie die Darstellung der Zeilen- und Spaltenüberschriften in der Pivot-Tabelle steuern:
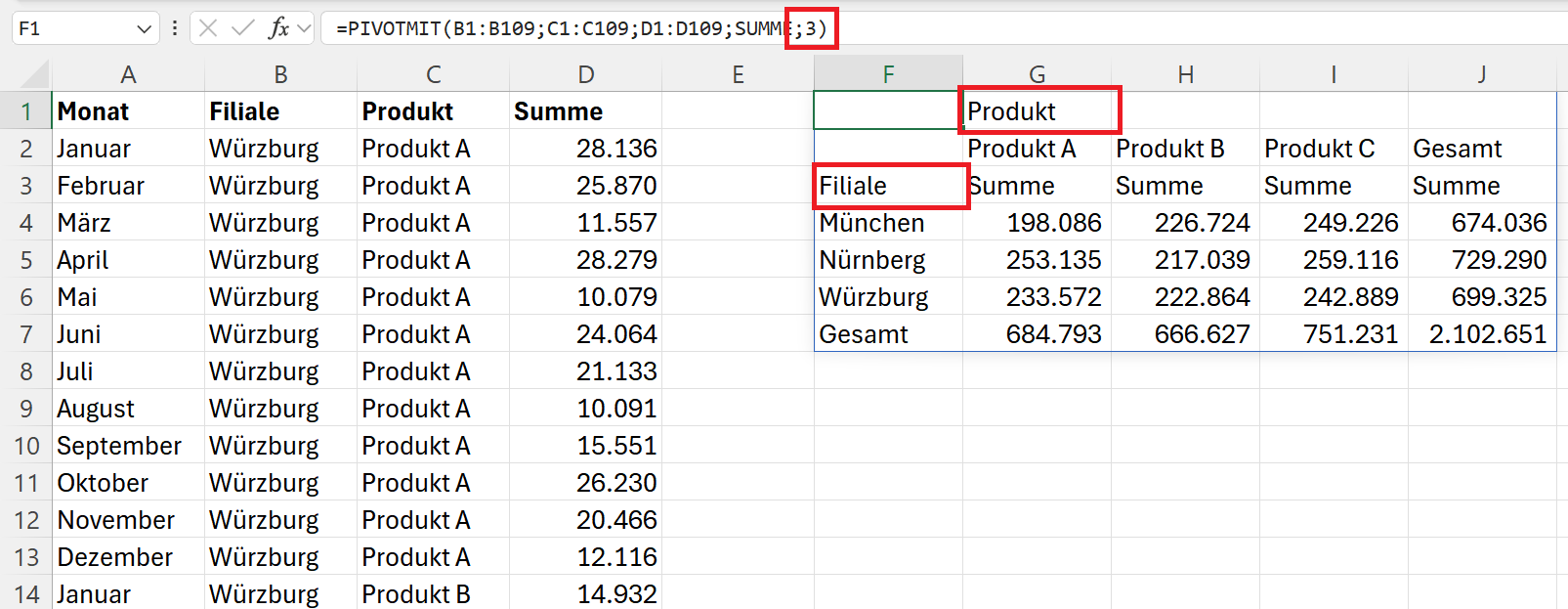
=PIVOTMIT(B1:B109;C1:C109;D1:D109;SUMME;3)
Durch die Zahl 3 können Sie zum Beispiel die Zeilen- und Spaltenüberschriften anzeigen lassen.
Gesamt- und Teilergebnisse anzeigen
Über die Argumente row_total_depth und col_total_depth können Sie die Anzeige der Zeilen- (row) und Spaltenergebnisse (col) steuern. Standardmäßig werden die Ergebnisse eingeblendet, wenn Sie kein Argument angeben. Die folgenden Einstellungen stehen Ihnen hier zur Verfügung:
- 0: Keine Gesamtsummen
- 1: Gesamtsummen
- 2: Gesamt- und Zwischensummen
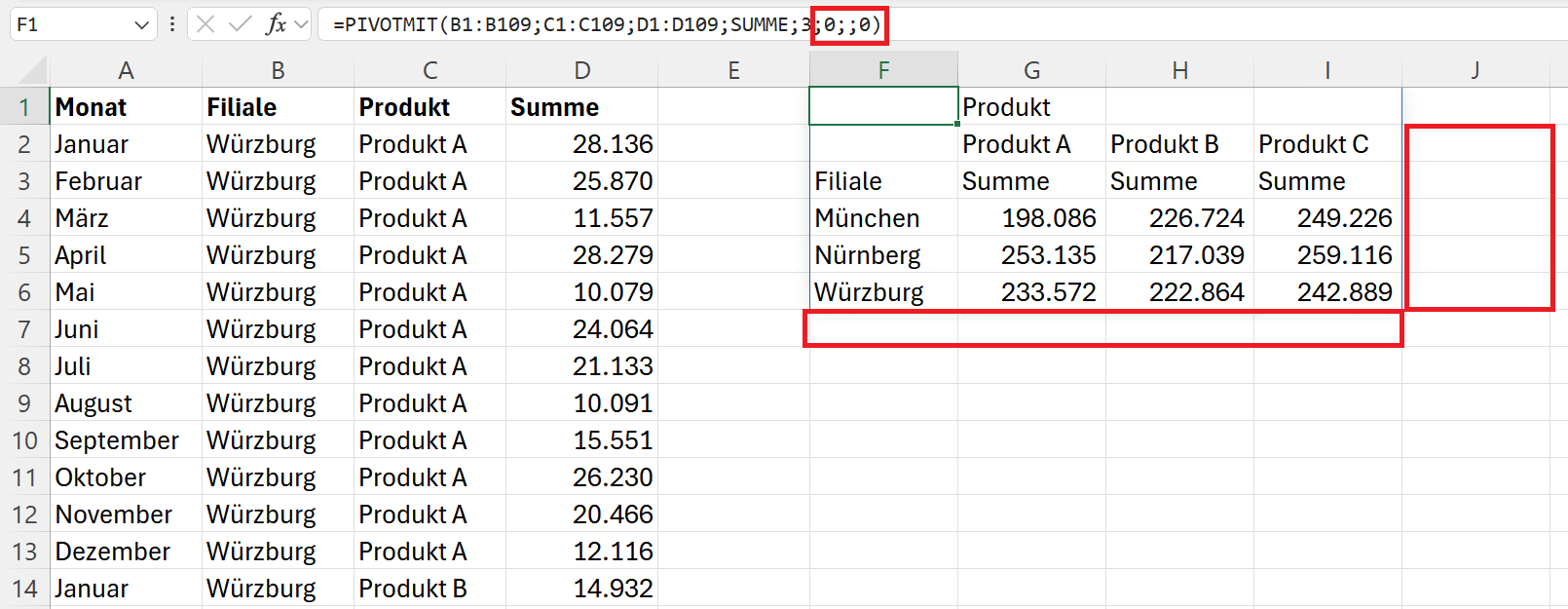
Wenn Sie die Ergebnisse nicht anzeigen lassen wollen, dann können Sie dies mit der folgenden Formel erreichen:
=PIVOTMIT(B1:B109;C1:C109;D1:D109;SUMME;3;0;;0)
Zeilen und Spalten sortieren
Über die Argumente row_sort_order und col_sort_order können Sie die Zeilen (row) und Spalten (col) sortieren. Standardmäßig werden die Zeilen und Spalten aufsteigend sortiert, wenn Sie kein Argument angeben. Die folgenden Einstellungen stehen Ihnen hier zur Verfügung:
- 1: aufsteigende Sortierung
- -1: absteigende Sortierung
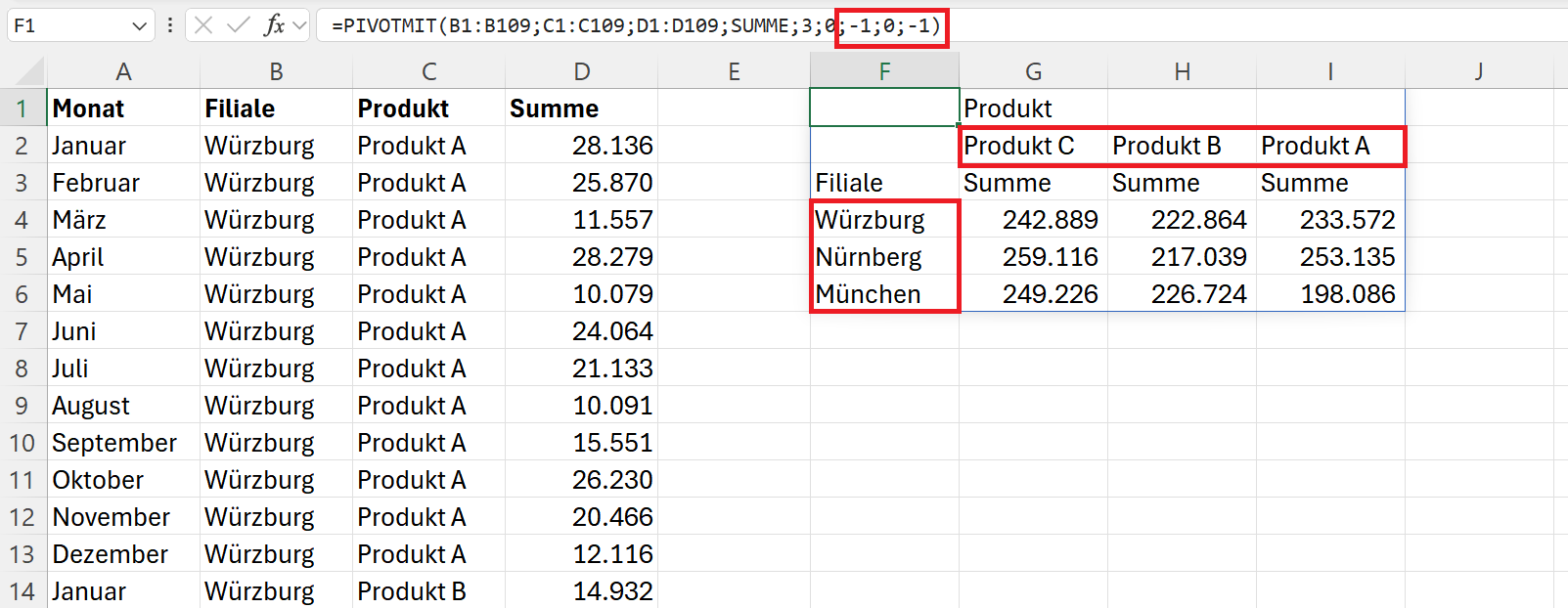
Wenn Sie die Zeilen und Spalten absteigend sortieren lassen wollen, dann können Sie dies mit der folgenden Formel erreichen:
=PIVOTMIT(B1:B109;C1:C109;D1:D109;SUMME;3;0;-1;0;-1)
Filter in der Pivot-Tabelle einsetzen
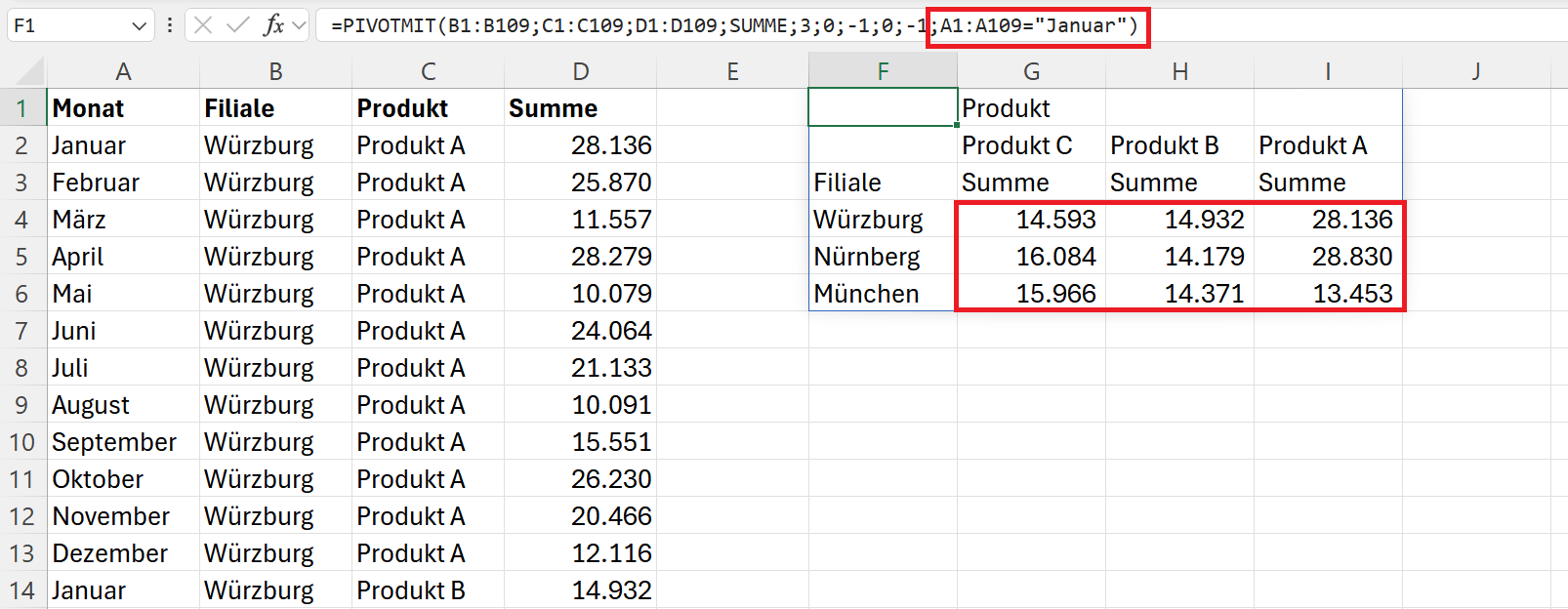
Analog zu den herkömmlichen Pivot-Tabellen können Sie über das Argument filter_array auch einen Filter definieren. Wollen Sie zum Beispiel nur die Werte des Monats Januar summieren und anzeigen lassen, dann können Sie hierfür die folgende Formel verwenden:
=PIVOTMIT(B1:B109;C1:C109;D1:D109;SUMME;3;0;-1;0;-1;A1:A109="Januar")
Vorteile von PIVOTMIT()
- Effizienz: Keine manuelle Erstellung oder Anpassung von Pivot-Tabellen.
- Dynamik: Ändern sich Ihre Daten, wird die Formel automatisch aktualisiert – keine Refresh-Aktion erforderlich.
- Flexibilität: Perfekt für den Einsatz in komplexen Dashboards oder Berichten.
- Kompaktheit: Ideal für Nutzer, die Formeln bevorzugen, um Tabellen zu automatisieren.
Wann sollten Sie PIVOTMIT() verwenden?
- Für schnelle Analysen: Sie möchten Daten gruppieren und aggregieren, ohne Zeit mit der Pivot-Tabellen-Erstellung zu verlieren.
- In dynamischen Berichten: PIVOTMIT() integriert sich nahtlos in andere Formeln und passt sich an Datenänderungen an.
- In Kombination mit anderen Funktionen: Verwenden Sie PIVOTMIT() zusammen mit Funktionen wie FILTER(), SORTIEREN() oder TEXTVERKETTEN() für noch mächtigere Berichte.
Grenzen der Funktion
Auch wenn PIVOTMIT() viele Vorteile bietet, gibt es ein paar Einschränkungen:
- Sie ist für extrem große Datenmengen möglicherweise nicht so performant wie klassische Pivot-Tabellen.
- Die visuelle Anpassung ist eingeschränkt – klassische Pivot-Tabellen bieten mehr Layout-Optionen.
Fazit
Die PIVOTMIT()-Funktion macht die Welt der Datenanalysen zugänglicher, schneller und dynamischer. Mit dieser Funktion können nicht nur Anfänger, sondern auch fortgeschrittene Excel-Nutzer ihre Arbeitsweise erheblich vereinfachen.