Werte suchen in ExcelEinfache Datenanalyse in Excel mit GRUPPIERENNACH()
Mit der Funktion GRUPPIERENNACH() werten Sie Daten aus und stellen diese wie mit einer Pivot-Tabelle übersichtlich dar. Mit einer einzigen Funktion gruppieren Sie die Daten und berechnen Summen, Mittelwerte und andere Ergebnisse.
In diesem Beitrag lernen Sie die Funktionsweise von GRUPPIERENNACH() kennen. Sie sehen dies an einem Praxisbeispiel und Sie erfahren, warum diese Funktion ein Must-have für jeden Excel-Anwender ist.
Was ist die Funktion GRUPPIERENNACH()?
Die Funktion GRUPPIERENNACH() ist eine dynamische Matrixfunktion, die speziell dafür entwickelt wurde, Daten zu gruppieren und zusammenzufassen. Sie funktioniert ähnlich wie eine Pivot-Tabelle, jedoch direkt in einer Zelle – ohne manuelle Schritte oder komplizierten Tabellenaufbau.
Mit dieser Funktion können Sie:
- gruppieren nach einer oder mehreren Spalten,
- Werte automatisch summieren, zählen, den Durchschnitt berechnen oder andere Aggregationen durchführen,
- große Datensätze schnell übersichtlich zusammenfassen.
GRUPPIERENNACH() besitzt folgende Syntax:
=GRUPPIERENNACH(row_fields; values; function; [field_headers]; [total_depth]; [sort_order]; [filter_array]; [field_relationship])
row_fields: Ein spaltenorientiertes Array oder ein Bereich, der die Werte enthält, die zum Gruppieren von Zeilen und Generieren von Zeilenüberschriften verwendet werden. Dieser Bereich kann mehrere Spalten enthalten. Wenn ja, enthält die Ausgabe Gruppen und Untergruppen (Zeilengruppenebenen).
values: Ein spaltenorientiertes Array oder ein Bereich der zu aggregierenden Daten. Diese Daten (Werte) werden zu den Gruppen zusammengefasst und berechnet (siehe function). Das Array oder der Bereich kann mehrere Spalten enthalten. Wenn ja, enthält die Ausgabe mehrere Aggregationen.
function: Eine Funktion wie SUMME, MITTELWERT oder ANZAHL, die zur Aggregation von Werten verwendet wird. Es kann auch ein Vektor von Lambdas bereitgestellt werden. Wenn ja, enthält die Ausgabe mehrere Aggregationen. Die Ausrichtung des Vektors bestimmt, ob sie zeilen- oder spaltenweise angeordnet sind.
field_headers: Eine Zahl, die angibt, ob die Spalte(n) mit den row_fields Header (Spaltenüberschriften) aufweisen und ob die Überschriften in den Ergebnissen angezeigt werden sollen. Mögliche Werte sind:
- Fehlt: Automatisch (Standard)
- 0: Nein, enthält keine Spaltenüberschrift
- 1: Ja, enthält Spaltenüberschrift, aber nicht anzeigen
- 2: Nein, enthält keine Spaltenüberschrift, aber Spaltenüberschrift generieren
- 3: Ja, enthält Spaltenüberschrift und anzeigen
total_depth: Bestimmt, ob die Zeilenüberschriften Summen enthalten sollen. Die folgenden Werte sind möglich:
- Fehlt: Automatisch, Gesamtsummen und nach Möglichkeit Zwischensummen (Standard)
- 0: Keine Gesamtsummen
- 1: Gesamtsummen
- 2: Gesamtsummen und Zwischensummen
sort_order: Eine Zahl, die angibt, wie Zeilen sortiert werden sollen. Sortiert werden die Gruppen, also die Werte in row_fields. Gibt es mehrere Spalten für die Gruppierung (Gruppen und Untergruppen), dann gibt die Zahl bei sort_order an, welche Spalte für die Sortierung gewählt wird. Die folgenden Werte sind möglich:
- Fehlt: Automatisch, die Sortierung erfolgt aufsteigend oder alphabetisch nach der ersten Spalte (Standard)
- 1: die erste Spalte aus row_fields wird aufsteigend, alphabetisch von A bis Z sortiert
- -1: die erste Spalte aus row_fields wird absteigend, alphabetisch von Z bis A sortiert
- 2: die zweite Spalte aus row_fields wird aufsteigend, alphabetisch von A bis Z sortiert
- -2: die zweite Spalte aus row_fields wird absteigend, alphabetisch von A bis Z sortiert
- …
filter_array: Ein spaltenorientiertes Array boolescher Daten, das angibt, ob die entsprechende Datenzeile berücksichtigt werden soll. Sie können eine Bedingung formulieren, deren Ergebnis wahr oder falsch ist. Zeilen (Datensätze), die als Ergebnis „falsch“ haben, werden bei der Ausgabe nicht angezeigt.
field_relationship: Gibt die Beziehungsfelder an, wenn mehrere Spalten für row_fields bereitgestellt werden. Mögliche Werte sind:
- 0: Hierarchie (Standard); bei einer Hierarchiefeldbeziehung berücksichtigt die Sortierung späterer Feldspalten die Hierarchie früherer Spalten.
- 1: Tabelle; bei einer Tabellenfeldbeziehung erfolgt die Sortierung jeder Feldspalte unabhängig, ohne Hierarchie. Teilergebnisse werden nicht unterstützt, da sie von den Daten mit einer Hierarchie abhängen.
Was hier zunächst mit der allgemeinen Syntax der GRUPPIERENNACH-Funktion beschrieben ist, lässt sich anhand des folgenden Beispiels besser verstehen.
Praxisbeispiel: Umsatzanalyse für ein Unternehmen
Angenommen, Sie sind für die Analyse der monatlichen Umsätze in verschiedenen Regionen verantwortlich. Die folgenden Daten liegen wie folgt vor.
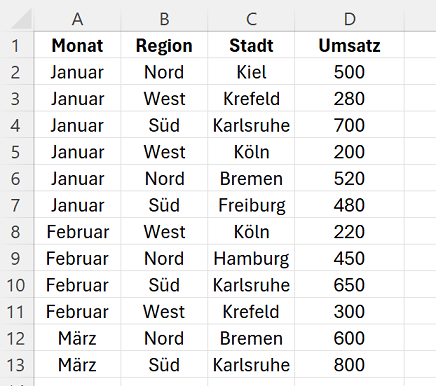
Sie sollen die Daten nun nach Region gruppieren und summieren. Hierfür können Sie die folgende, einfache Formel verwenden:
=GRUPPIERENNACH(B2:B13;D2:D13;SUMME)
- B2:B8 = row_fields = Namen der Regionen, nach denen gruppiert werden soll.
- C2:C8 = values = Werte, die je Region summiert werden sollen.
- SUMME = function = ist die Aggregatfunktion, die in der Gruppierung angewendet werden soll.
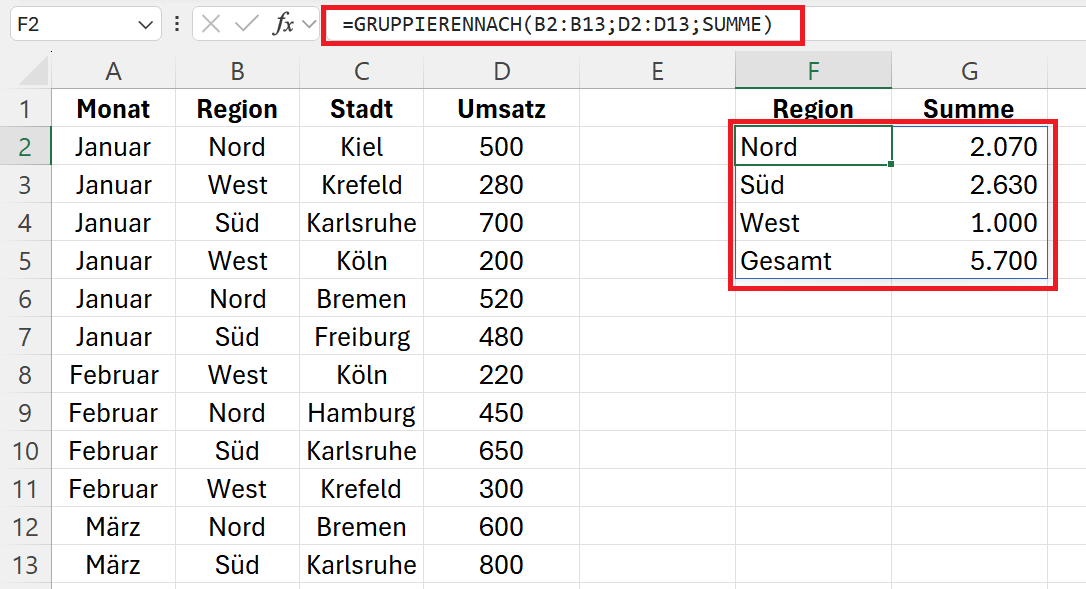
Diese einfachste Anwendung der GRUPPERENNACH()-Funktion summiert alle Werte in der Umsatzspalte basierend auf den eindeutigen Werten in der Spalte mit den Regionen. Dies geschieht vollautomatisch und ohne manuelle Sortierung oder Filterung.
Weitere Parameter der Funktion GRUPPIERENNACH()
Nun wird die Ausgabe Schritt für Schritt durch die weiteren möglichen Einstellungen zur Funktion GRUPPIERENNACH() erläutert.
Spaltenüberschriften anzeigen
Mit dem Parameter field_headers werden bei der Ausgabe die Spaltenüberschriften übernommen. Der Datenbereich hat also Spaltenüberschriften, und diese sollen bei der Ausgabe angezeigt werden. Der Parameter field_headers beträgt deshalb 3.
Die Funktion wird erweitert zu:
=GRUPPIERENNACH(B1:B13;D1:D13;SUMME;3)
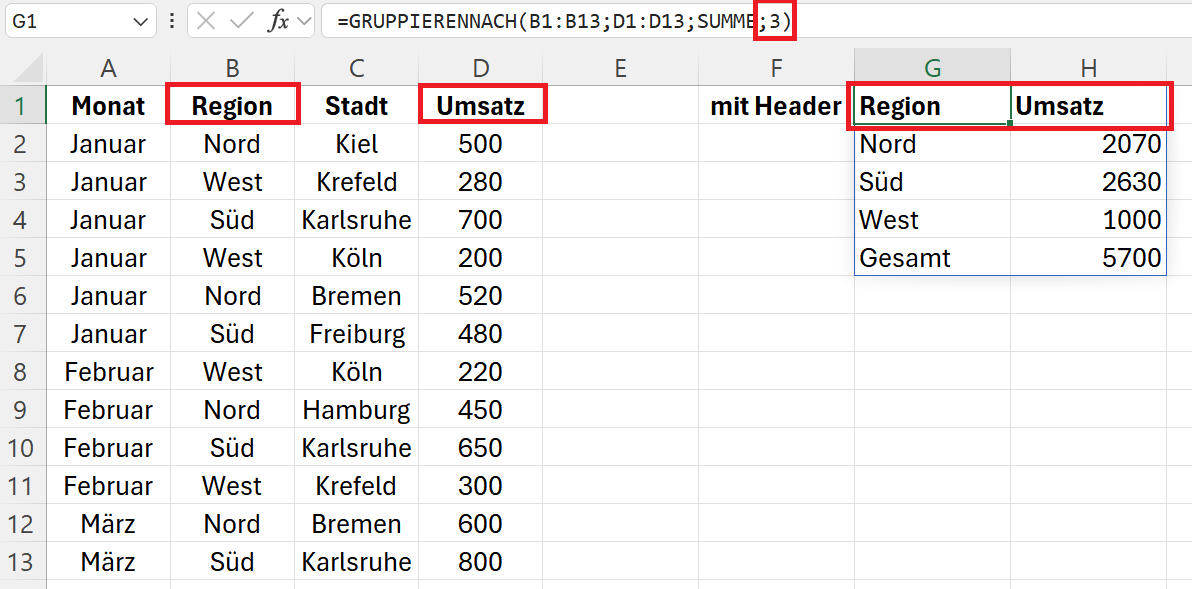
Ergebniszeilen anzeigen
Im nächsten Schritt soll keine Gesamtsumme angezeigt werden. Der Parameter total_depth erhält deshalb den Wert 0.
Die Funktion wird nochmals erweitert zu:
=GRUPPIERENNACH(B1:B13;D1:D13;SUMME;3;0)
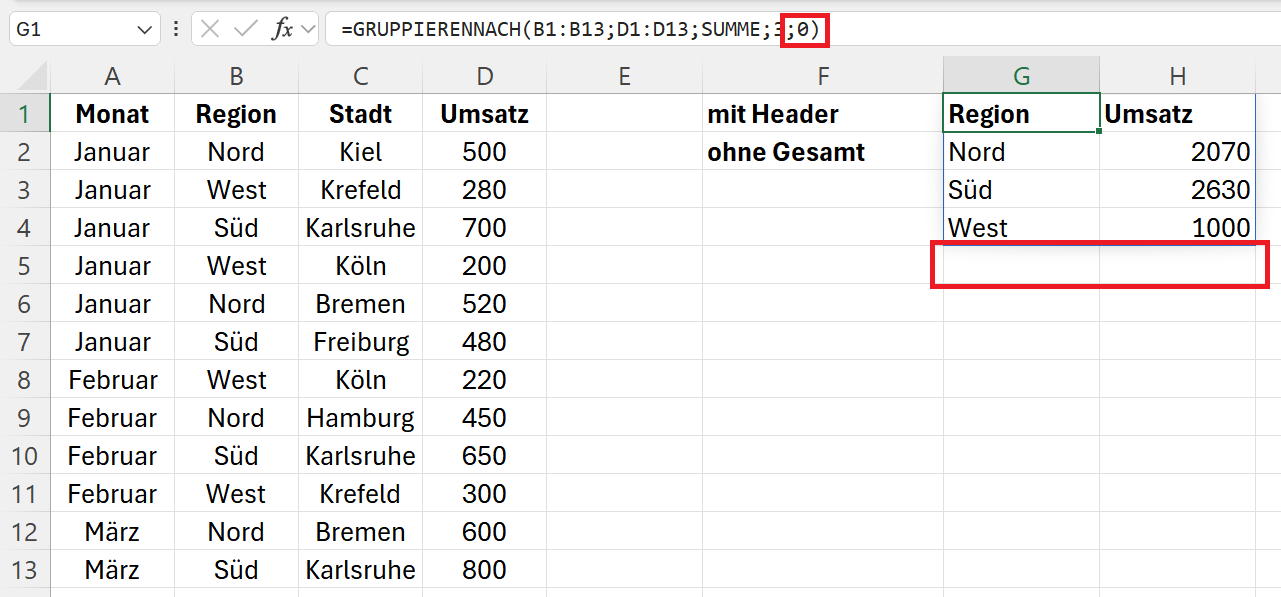
Ausgabe sortieren
Die Ausgabe der gruppierten Daten soll nun sortiert werden nach der Spalte Region, alphabetisch absteigend. Dazu wird dem Parameter sort_order der Wert -1 zugewiesen. Die Regionen werden in der Folge von Z bis A alphabetisch sortiert.
Die Funktion wird erweitert zu:
=GRUPPIERENNACH(B1:B13;D1:D13;SUMME;3;0;-1)
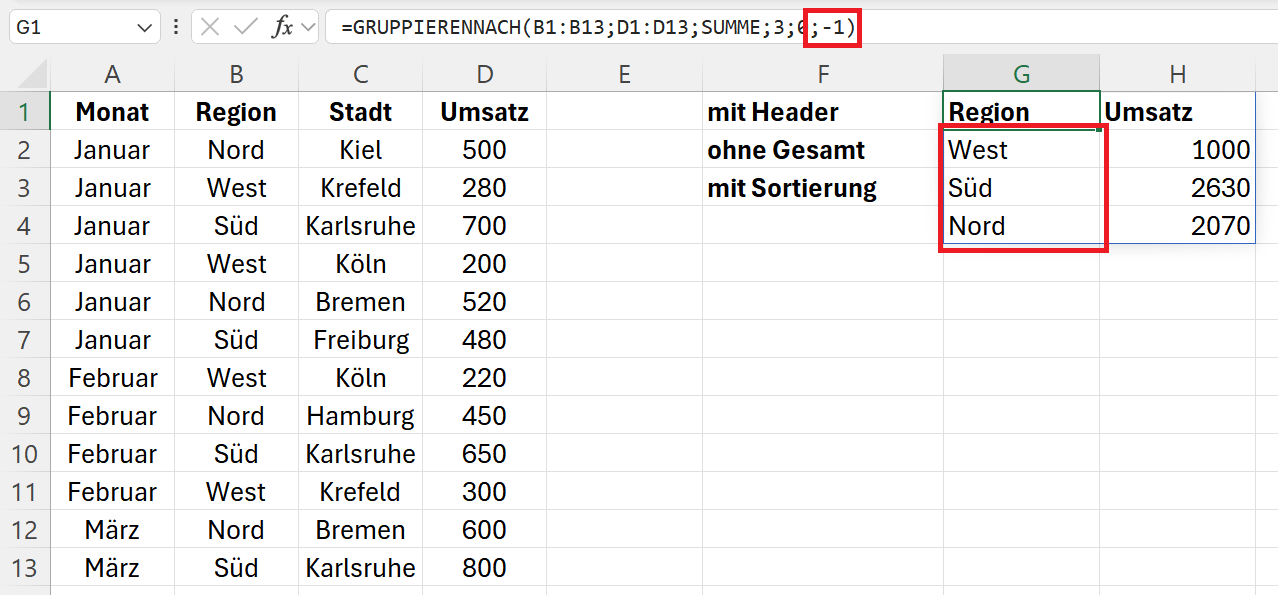
Im nächsten Beispiel soll die Spalte „Stadt“ in die Ausgabe einbezogen werden. Die Sortierung der Ausgabe soll nach dem Kriterium „Stadt“ von Z bis A erfolgen. Deshalb lautet der Parameter -2. Es wird die zweite Header-Spalte für die Sortierung genutzt, und diese soll alphabetisch von Z bis A sortiert werden. Die Funktion lautet entsprechend:
=GRUPPIERENNACH(B1:C13;D1:D13;SUMME;3;0;-2)
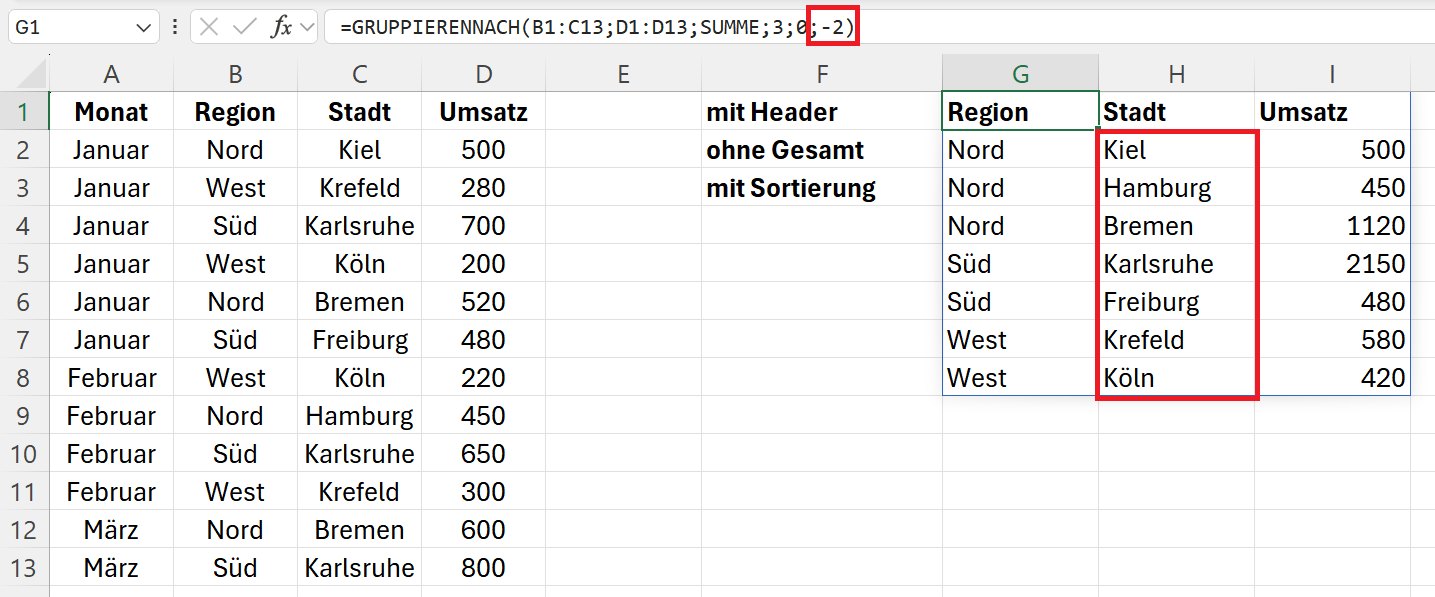
Das Ergebnis zeigt, dass die Sortierung in der Untergruppe „Stadt“ nur innerhalb der übergeordneten Gruppe „Region“ erfolgt. Die Region wird alphabetisch sortiert und in der Region „Nord“ werden die Städte alphabetisch von Z bis A sortiert.
Filter einsetzen
Mit dem Parameter filter_array können Sie Kriterien definieren, nach denen Zeilen (Datensätze) aus der Ausgabe herausgefiltert werden. Im Beispiel soll das Ergebnis aus Kiel nicht berücksichtigt werden. Dann lautet die erweiterte Funktion:
=GRUPPIERENNACH(B1:C13;D1:D13;SUMME;3;0;-2;C1:C13<>"Kiel")
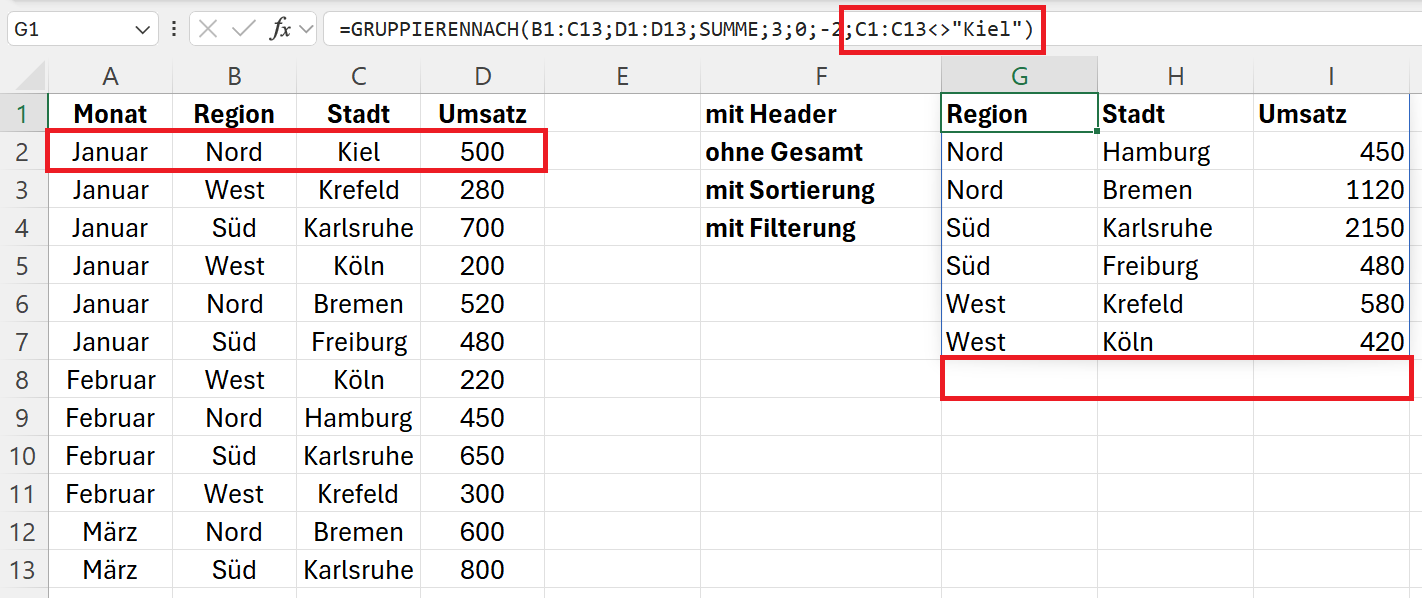
Hierarchie der Gruppierung beachten
Da im Beispiel zwei Kriterien für die Gruppierung genutzt werden (Region und Stadt) können Sie mit dem Parameter field_relationship einstellen, ob bei der Sortierung die Hierarchie der Gruppierung beachtet werden soll oder nicht. Bei der Standardeinstellung wird die Gruppe „Region“ ausgegeben und sortiert und dann – innerhalb dieser Gruppe – die Untergruppe „Stadt“ ausgegeben und sortiert.
Soll diese Hierarchie nicht beachtet werden, dann wählen Sie für den Parameter den Wert 1, wie im folgenden Beispiel. Die Funktion lautet:
=GRUPPIERENNACH(B1:C13;D1:D13;SUMME;3;0;-2;C1:C13<>"Kiel";1)
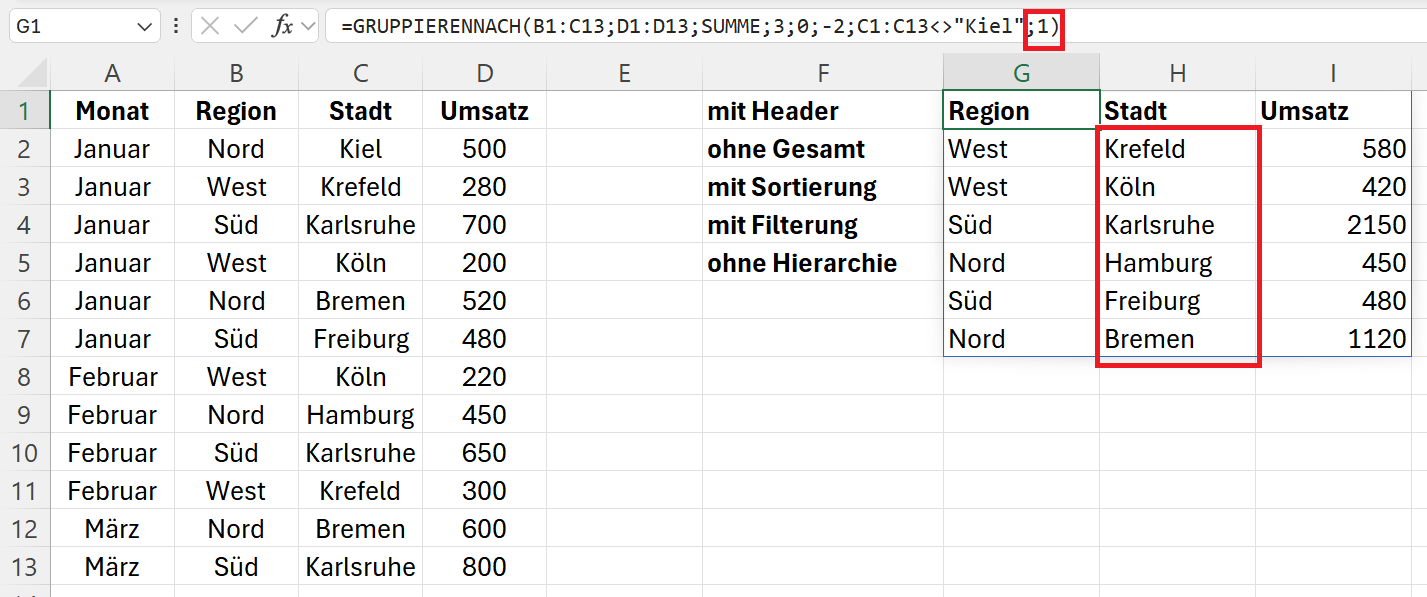
Die Sortierung der Ausgabe erfolgt nur nach dem Kriterium „Stadt“, in der angegebenen Reihenfolge alphabetisch von Z bis A. Die übergeordnete Gruppierung „Region“ wird nicht berücksichtigt.
Warum ist GRUPPIERENNACH() ein Gamechanger?
- Effizienz: Kein langwieriges Setup von Pivot-Tabellen mehr.
- Flexibilität: Funktioniert perfekt mit dynamischen Daten und Arrays.
- Automatisierung: Ideal für Dashboards und Berichte, die sich mit den zugrundeliegenden Daten automatisch aktualisieren.
- Leicht verständlich: Die Syntax ist intuitiv und schnell anzuwenden.
- Mit dynamischen Arrays kombinieren: Nutzen Sie GRUPPIERENNACH() mit Funktionen wie FILTER() oder SORTIEREN() für noch mächtigere Analysen.
- Benutzerdefinierte Aggregationen: Wenn Standardfunktionen wie SUMME oder ANZAHL nicht ausreichen, können Sie benutzerdefinierte LAMBDA()-Funktionen integrieren.
Die neue GRUPPIERENNACH()-Funktion spart Zeit, reduziert Fehler und bringt die Datenanalyse auf ein neues Niveau. Sie eignet sich perfekt für alle, die große Datenmengen schnell und übersichtlich zusammenfassen möchten.
Probieren Sie es aus und stellen Sie die Parameter so ein, bis die Ausgabe Ihren Erwartungen entspricht. Es ist wirklich sehr einfach!