Data-Mining – DatenanalyseMethoden für deskriptive Statistik und Datenanalyse
Statistik für die Datenanalyse im Unternehmen
Viele Menschen schrecken zurück, wenn das Wort Statistik fällt. Unschöne Erinnerungen an Schulzeit oder Studium kommen auf, als man von mathematischen Formeln und Zahlenwüsten gequält wurde. Dabei ist ein Grundverständnis von Statistik im Berufsleben hilfreich, wenn nicht sogar notwendig. Dafür müssen Sie sich jedoch nicht wieder mit mathematischen Formeln quälen, das übernehmen heutzutage Computer mit Spezialsoftware oder einfach Excel.
Statistik ist in der Mathematik ein weites Feld, im Unternehmenskontext wird jedoch in der Regel nur ein Bruchteil davon benötigt. Beim Data-Mining geht es zunächst speziell um deskriptive Statistik. „Deskriptiv“ meint beschreibend. Das Data-Mining soll eine beschreibende Zusammenfassung von Daten liefern. Diese Zusammenfassung kann mit Zahlen oder Grafiken erfolgen, beide Varianten haben ihre jeweiligen Vor- und Nachteile.
Woher kommen die Daten für die deskriptive Statistik?
Um deskriptive Statistik anwenden zu können, werden zuerst Daten benötigt, die beschrieben werden sollen. In Unternehmen und im Hinblick auf betriebswirtschaftliche Fragen entstehen Daten in unterschiedlichsten Varianten aus unterschiedlichsten Quellen. Beispiele sind Daten aus:
- Produktionsprozessen wie Rüstzeiten, Durchlaufzeiten, produzierte Stückzahlen
- Qualitätskontrolle: Produktfehler, Abweichungen bei Prozessparametern, Nacharbeit, Ausschuss
- Materialwirtschaft: Energieverbrauch, Materialverbrauch, Abfall
- Buchhaltung: Rechnungen, Rechnungsbeträge, Zahlungen
- Vertrieb: Angebote, Bestellungen, Erstkäufe, Warenkörbe
- Marketing: Response-Raten, Kundenmerkmale, Marktdaten, Wettbewerbsdaten
- Kundenservice: Beschwerden, Anrufe im Callcenter
Im Folgenden sollen die Möglichkeiten des Data-Mining und der Datenanalyse am Beispiel eines fiktiven Callcenters erläutert und illustriert werden.
Beispiel für Datenanalyse: Datenquelle Callcenter
Die Telefonanlage des Callcenters erfasst für jeden Anruf Zeitpunkt, Gesamtdauer, Verweildauer in der Warteschleife, das Anliegen und den Mitarbeiter, der sich um das Anliegen kümmert. Einmal in der Woche werden diese Daten als Wochenstatistik analysiert, um ein definiertes Qualitätsniveau den Kunden gegenüber sicherstellen zu können. Dazu wird insbesondere auf die Verweildauer in der Warteschleife geachtet.
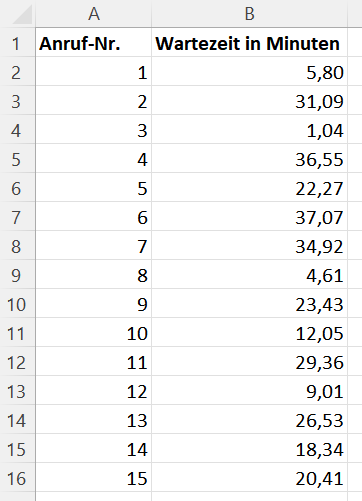
Der Beispieldatensatz der laufenden Woche im Callcenter enthält insgesamt 19.155 Anrufe. Für jeden Anruf wurde der Wochentag und die Stunde erfasst, in welcher der Anruf erfolgt ist. Zudem wurde die Wartezeit erfasst, bis das Gespräch von einem Mitarbeiter angenommen werden konnte. Einen kleinen Ausschnitt aus dem Datensatz zeigt die Tabelle in Abbildung 3.
Statistische Kennzahlen zur Datenbeschreibung
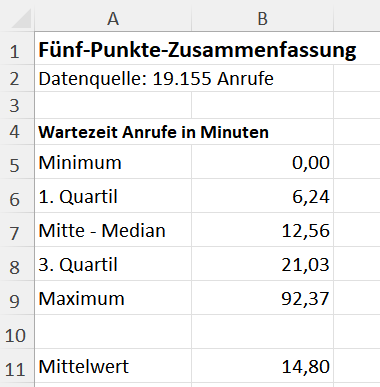
Für einen ersten groben Überblick verwendet die deskriptive Statistik eine Fünf-Punkte-Zusammenfassung, die die wichtigsten Lageparameter darstellt. Mithilfe von Lageparametern wird die Verteilung der Datenpunkte beschrieben; „wie die Daten liegen“. Die fünf Lageparameter der Fünf-Punkte-Zusammenfassung für einen Datensatz sind:
- Minimalwert
- Maximalwert
- Mitte
- erstes Quartil
- drittes Quartil
Diese Lageparameter werden folgendermaßen ermittelt und mit Excel-Funktionen berechnet:
Minimalwert und Maximalwert
Für die Wartezeit des Kunden am Telefon zeigt die Analyse den Minimalwert 0 Minuten und den Maximalwert 92,37 Minuten. In Excel gibt es dafür die Funktionen MIN() und MAX(), die nur die Wartezeit des Datensatzes (Spalte B in Abbildung 3) als Parameter benötigen.
Mitte der Verteilung
Der nächste Lageparameter beschreibt die Mitte der Verteilung. Dabei ist Vorsicht geboten, da es zwei unterschiedliche Arten der Mitte gibt:
- arithmetisches Mittel, auch als Durchschnitt oder Mittelwert bezeichnet
- Median
Der umgangssprachliche Durchschnitt als arithmetisches Mittel ist anfällig für Ausreißer, also für einzelne extreme Werte an den Enden der Verteilung. Besonders deutlich wird das zum Beispiel bei Einkommensverteilungen. Wenn in einem kleinen Ort ein Milliardär wohnt, ist das Durchschnittseinkommen sehr hoch – obwohl nur eine Person extrem viel Einkommen erzielt und alle anderen vielleicht sogar sehr wenig.
Eine höhere Aussagekraft hat hier der Median, der den mittleren Wert einer Verteilung beschreibt. Mittlerer Wert bedeutet, dass die Hälfte der Werte darüber liegt und die andere Hälfte darunter. Der eine Milliardär würde also den Median nicht verschieben, da die Mitte der Einkommen sich nicht verändert.
Diese Unterscheidung gibt es in Excel auch. Die Funktion MITTELWERT() berechnet das arithmetische Mittel, die Funktion MEDIAN() entsprechend den Median. Die Wartezeiten des Callcenters haben einen Mittelwert von 14,80 Minuten und einen Median von 12,56 Minuten. Aus der Differenz der Werte lässt sich schon erahnen, dass es wohl ein paar Ausreißer nach oben gibt, denn das arithmetische Mittel ist größer als der Median.
Quartile
Die zwei weiteren Kennzahlen zur Fünf-Punkte-Zusammenfassung sind das erste und das dritte Quartil. Der Name Quartil impliziert bereits eine Vierteilung des Datensatzes – und genau das ist es auch. Das erste Quartil enthält 25 Prozent der Datenpunkte des Datensatzes, das dritte dementsprechend 75 Prozent. Prinzipiell könnte der Median auch als 50-Prozent-Quartil aufgefasst werden, diese Bezeichnung ist aber unüblich.
Für die Berechnung der Quartile bietet Excel eine passende Funktion: QUARTILE.INKL(). Bei der Auswahl der Formel ist Vorsicht geboten, Excel kennt sowohl QUARTILE.INKL() als auch QUARTILE.EXKL(). Beide Formeln unterscheiden sich etwas in Details der Berechnung, was im Normalfall aber keinen Unterschied im Ergebnis ausmacht. Da jedoch die zwei bei Datenanalysen beliebten Programmiersprachen R und Python die Quartile nach der gleichen Formel wie QUARTILE.INKL() berechnen, sollten Sie diese verwenden. Aus Kompatibilitätsgründen gibt es übrigens auch noch die Formel QUARTILE(), von deren Verwendung aber sogar Microsoft abrät.
Für den Beispieldatensatz aus dem Callcenter sind die Werte: 6,24 Minuten für das erste Quartil und 21,03 Minuten für das dritte. Das bedeutet, dass 25 Prozent der Anrufer weniger als 6,24 Minuten warten und 75 Prozent der Anrufer warten nicht länger als 21,03 Minuten.
Quartile sind Quantile mit Eigennamen
Für die Analyse von Daten können nicht nur die 25-Prozent-, 50-Prozent- oder 75-Prozent-Grenze betrachtet werden; also unteres Quartil, Median und oberes Quartil. Für die Datenanalyse können auch andere Grenzen gezogen werden, für die überprüft wird, wie viele Messwerte auf der einen Seite der Grenze und wie viele auf der anderen Seite liegen.
Diese definierten Grenzen werden als Quantile bezeichnet. Dabei muss angegeben werden, welche Grenze damit gemeint ist. Die Schreibweise lautet: p-Quantil. Dabei ist p ein Wert zwischen 0 und 1, der angibt, wo die Grenze liegt.
Beispiel: Der Wert für das 0,1-Quantil bedeutet, dass 10 Prozent der Messwerte kleiner sind als dieser Wert und 90 Prozent größer.
Tabellarische Datenanalyse
Diese beschreibenden Kennzahlen des Datensatzes aus dem Callcenter sind in Abbildung 4 in einer Tabelle aufgeführt. Da nur die Werte für die fünf beschreibenden Kennzahlen genannt sind, wird dies auch als tabellarische Analyse der Daten bezeichnet.
Grafische Datenanalyse
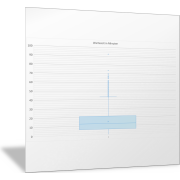
Diese fünf Werte (ohne Durchschnitt) lassen sich auch in einer einzelnen Grafik darstellen, dem sogenannten Boxplot. In der Statistik werden Boxplots häufig verwendet, um die Verteilung von Daten grafisch sichtbar und besser verständlich zu machen. Bequemer Weise bringt Excel seit der Version 2016 auch eine Diagrammvorlage dafür mit.
Um einen Boxplot zu erstellen, müssen Sie nur die Datenreihe mit den Wartezeiten markieren und im Menü Einfügen – Diagramme – Register Alle Diagramme die Kastengrafik wählen. Das Ergebnis für den Datensatz mit den 19.155 Werten zeigt Abbildung 5.

Boxplot-Diagramm für die deskriptive Statistik einsetzen
Der Ausreißer nach oben sticht sofort ins Auge. Ein Anrufer hat mehr als 90 Minuten gewartet – das ist das Maximum von 92,37 Minuten. Es ist aber beruhigend zu sehen, dass das tatsächlich ein extremer Ausreißer ist, die anderen einzelnen Punkte sind zwar auch Ausreißer, aber nicht so extreme.
In der Mitte des Diagramms ist eine blaue Box, die dem Diagramm den Namen gibt. In dieser Box sind dargestellt:
- der Median als horizontale Linie; hier liegt die Mitte der Verteilung, 50 Prozent der Messwerte unterhalb dieser Linie, 50 Prozent darüber
- der Durchschnitt oder Mittelwert ist mit einem kleinen Kreuz markiert, was zwar nicht der statistischen Definition eines Boxplots entspricht, aber auch nicht stört
Die blaue Box repräsentiert die mittleren 50 Prozent der Verteilung. Ihre untere Begrenzung wird vom ersten Quartil gebildet, die obere vom dritten.
Oben und unten ragen aus der Box noch Linien, die sogenannten „Antennen“, „Fühler“ oder „Whiskers“ heraus. Die Länge der Fühler ist 1,5-mal die Höhe der Box; der sogenannte Interquartilsabstand oder englisch IQR. Alle Werte, die noch weiter weg sind, werden als Ausreißer bezeichnet; sie sind als einzelne Punkte im Diagramm dargestellt.
Ein Boxplot enthält also die gleichen Informationen wie eine Fünf-Punkt-Zusammenfassung, ist jedoch grafisch schneller zu erfassen. Man sieht auf den ersten Blick:
- die Streuung der Datenpunkte,
- wie weit die Messwerte reichen,
- ob es Ausreißer gibt und
- in welchem Wertebereich die meisten Daten liegen.
Histogramm zur Datenanalyse
Man kann in einem Boxplot allerdings nur die Streuung der Datenpunkte sehen, nicht die Verteilung – wie viele Kunden also wie lange gewartet haben. Das erkennt man gut in einem Histogramm, in dem die Werteskala (die Minuten) in einzelne gleich große Bereiche eingeteilt wird und die Höhe eines Balkens angibt, wie viel Datenpunkte in dem jeweiligen Bereich liegen.
Zum Glück gibt es dafür eine Vorlage in Excel. Im Menü Einfügen – Diagramme – Register Alle Diagramme das Histogramm. Mit dieser Diagramm-Vorlage teilt Excel die Werte in Klassen oder Wertebereiche ein (x-Achse) und zählt, wie viele Werte in diesen Bereich fallen; diese Anzahl wird als Säule angezeigt (y-Achse). Sie können die Klassengröße auf der x-Achse in Excel einstellen.
Mit dem Histogramm in Abbildung 6 können Sie erkennen, dass ein großer Teil der Anrufer nicht länger als 21 Minuten wartet. Das ist keine Überraschung, das 3. Quartil liegt schließlich bei 21,03 Minuten. Und die Anzahl der Anrufer mit langer Wartezeit nimmt danach rapide ab.

Mit den beiden Diagrammen, Boxplot und Histogramm, können Sie schon eine ganze Menge aus Ihren Daten ablesen. Und je nachdem, für welchen Einsatzzweck Sie analysieren, sind die Lageparameter als Zahlen oder als übersichtliche Grafik vorteilhafter. Auch wenn das nur grundlegende Werkzeuge der Statistik sind, können Sie mit diesen Mitteln schon erstaunlich viel Informationen für unternehmerische Entscheidungen aus Ihren Daten gewinnen.
Datenquelle und Datenanalyse vorbereiten
Klären Sie für Ihre Datenquelle und Ihren Datensatz, welchen Messwert oder Parameter Sie mit der Fünf-Punkte-Zusammenfassung beschreiben wollen. Halten Sie dazu fest:
- Welche Information ist für Sie wichtig oder interessant?
- Warum ist diese Information wichtig oder interessant?
- Welcher Messwert oder Parameter aus Ihrem bestehenden Datensatz ist geeignet, um diese Information zu liefern?
Ermitteln Sie, in welcher Form die Daten und Datensätze vorliegen. Für eine Auswertung in Excel müssen die Datensätze gegebenenfalls vorher in die Excel-Datei als Datenquelle eingebunden werden.
Datensatz in Excel importieren
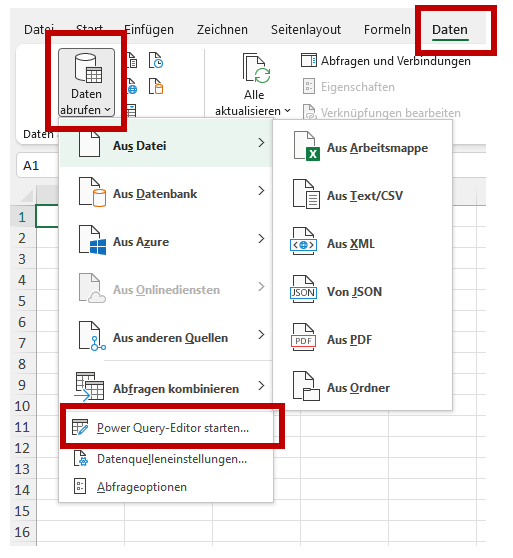
Falls die Daten noch nicht in Ihrer Excel-Datei vorliegen, müssen Sie diese über die Funktion Daten abrufen importieren. Wählen Sie dazu im Menü Daten – Daten abrufen und transformieren – Daten abrufen (siehe Abbildung 4).
Excel bietet dort unterschiedliche Möglichkeiten, Daten zu importieren. Oft liegen Daten im Format CSV vor, die Sie darüber importieren können. Eine besondere Möglichkeit, Daten zu importieren, ist die Funktion Power-Query.
Lageparameter für den Datensatz berechnen
Erstellen Sie dann mit dem importierten Datensatz die Fünf-Punkte-Zusammenfassung mit den wichtigen Lageparametern für Ihren ausgewählten Parameter; das ist im Allgemeinen eine ausgewählte Spalte in Ihrem importierten Excel-Datensatz.
Nutzen Sie dazu folgende Excel-Funktionen, wobei Werte dem Bereich entsprechen, den Sie auswerten wollen. Zum Beispiel: Werte = B2:B19155
- Minimum: =MIN(Werte)
- Quartil: =QUARTILE.INKL(Werte;1)
- Median: =MEDIAN(Werte)
- Quartil: =QUARTILE.INKL(Werte;3)
- Maximum: =MAX(Werte)
Oft wird die Fünf-Punkte-Zusammenfassung mit diesen Kennzahlen ergänzt um die Kennzahl Mittelwert oder Durchschnitt. Die Excel-Funktion dafür lautet: =MITTELWERT(Werte). Diese Kennzahl ist aber empfindlich bei Ausreißern und gehört deshalb nicht zu den robusten Kennzahlen der Fünf-Punkte-Zusammenfassung.
Diagramme für die Datenanalyse erstellen
Erstellen Sie ein Boxplot-Diagramm und ein Histogramm. Sie können die folgende Mustervorlage für Ihren Test nutzen.
Markieren Sie in der Tabelle DATEN aus der Vorlage den Bereich C2:C19155. Wählen Sie in Excel:
- Menü Einfügen – Diagramme – Register Alle Diagramme das Kastendiagramm
- Menü Einfügen – Diagramme – Register Alle Diagramme das Histogramm
Entsprechend verfahren Sie mit den Daten aus Ihrem Datensatz, den Sie auswerten wollen.
Nachdem Sie nun ein paar Werkzeuge für das Data-Mining kennengelernt haben, sollen diese bei einer explorativen Datenanalyse eingesetzt werden. Dabei wird versucht, unterschiedliche Fragestellungen mit dem Datensatz zu beantwortet. Welche statistischen Methoden für die Datenanalyse eingesetzt werden, erfahren Sie im folgenden Abschnitt dieses Handbuch-Kapitels.